-
gover-html に font-family を指定する PR を出した`go tool cover -html` の出力が素朴すぎるのでもう少しリッチな表現をしてくれるツールないかなぁと探していた。 探していたところ、[gocov]( + gocov-html が良さそ2025-07-04(Fri)
-
Jetbrains IDE の左下のパスっぽいやつは Navigation Bar という名前2025-06-27(Fri)
-
pgx.Connect は thread safe ではない> failed to deallocate cached statement(s): conn busy pgx/v5 で上記みたいなエラーが出まくったばあいは、`pgx.Connect()` を2025-06-26(Thu)
-
PostgreSQL で sqlc を使うときは、最初から `sql_package: pgx/v5` を指定しようsqlc+PostgreSQL では [COPY Protocol]( を使って複数行のインサートをする機能が提供されている。 これはめちゃくちゃ便利で,例えば以下のようなクエリがあったとする。2025-06-26(Thu)
-
Zod> TypeScript-first schema validation with static type inference2025-06-22(Sun)
-
エレコム 旅行用 圧縮袋 パッキングキューブ Mサイズ 12L 24×34×14㎝ 両面収納 コーデュラ 高耐久YKK製ファスナー採用 ブラック BMA-TRCS01MBK2025-06-21(Sat)

-
knative serving とknative のバージョンごとに対応している k8s のバージョンが違う。2025-06-20(Fri)
-
sqlc で INTERVAL するときの書き方PostgreSQL前提。 `WHERE created_at < NOW() - INTERVAL $1` みたいな書き方すると、$1 が整数とされる上に、名前が Column1 とかになってしま2025-06-19(Thu)
-
Aqua Voicemac のアプリなのだが、音声認識の精度が高いらしい。気がむいたら試してみたい2025-06-18(Wed)
-
僕には鳥の言葉がわかる2025-06-17(Tue)

-
jawiki-kana-kanji-dict を直したなんかよくわからんけど lindera-cli のオプションが微妙に変わってて動かなくなってたので修正。2025-06-10(Tue)
-
KeyScripten を tauri 2.0 に対応させたtauri 1.0 から 2.0 への移行、まぁまぁ大変。。 ```bash npm install @tauri-apps/cli@latest npm run tauri migrate `2025-06-08(Sun)
-
Go開発に最適な構成:TypeSpec + ogen + sqlc + orval + MSW + Docker Compose + Taskfile で爆速プロトタイピング最近、**Go(Golang)** の開発プロジェクトでは以下のような構成を採用していて、開発体験がかなり快適になっている。 * API定義:**TypeSpec** * バックエンド生成:**og2025-06-06(Fri)
-
typespec で utcDateTime を使ってるときに example を書く方法``` @example(#{ created: utcDateTime.fromISO("2020-01-01T00:00:00Z") }) model Entry { @encode(Da2025-06-05(Thu)
-
go のテストの結果を見やすくするには gotestsum が便利golang 初心者として日々を過ごしておるわけですが、`go test ./...` とかしたときに結局どれが FAIL したのかわからなくて目 grep することになって辛かった。 そういう場合2025-05-28(Wed)
-
本好きの下剋上を読破した思ったより綺麗に話がまとまっていて面白かった。 最初はドクターストーンみたいな話かと思って読み始めたけど全然違ったわ。2025-04-03(Thu)
-
さくらのクラウド検定 v1.0 に合格した2025-03-28(Fri)

-
Biome 2.0 では Plugin が書けるPlugin が GritQL という DSL で書けるようになるとのこと。 GritQL を知らなかったが、AST 検査を DSL でやるっていうのは最適化が出来そうで面白いね GritQL2025-03-26(Wed)
-
Wolfenstein Youngbloodナチスと戦うFPS。 2人協力プレイゲームだけど、わりといい感じにAIが動いてくれるのでソロプレイでも普通に遊べる。 ステルスにパラメーター振って遊んでもいいし、脳筋で遊んでもいい。結局、ボス戦は脳筋2025-03-23(Sun)
-
s3surferREADME にコマンド例がのってなかったけど以下でインストール出来る。 ```sh go install github.com/hirose31/s3surfer/cmd/s3surfer@lat2025-03-18(Tue)
-
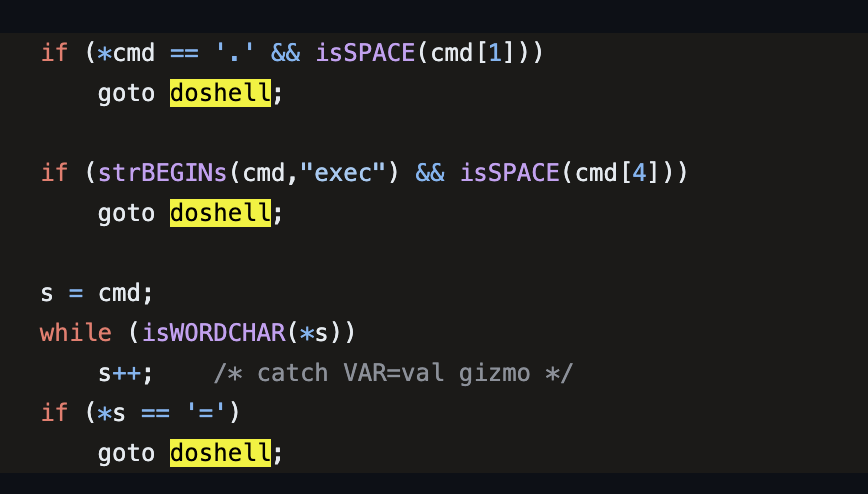
Perl5 の system でシェルが実行される条件2025-03-11(Tue)
-
backstopjsビジュアルリグリッションテストが出来るツール。 最近仕事で sphinx のバージョンアップをしていたのだが、バージョンアップしたらどのように変わるかを判定するために利用した。 めっちゃ便利。2025-03-07(Fri)
-
tview - golang 用の TUI ライブラリtcell をベースにしているらしい 最初、chatgpt がオススメしてきた textual - Python 用の TUI ライブラリ を使ってみたのだが、どうも細かい仕様が微妙だったので2025-03-07(Fri)
-
textual - Python 用の TUI ライブラリPython 用の TUI ライブラリ。試してみた結果、結構使いやすかった。 が、TextViewer ウィジェットが欲しかったのに、TextEditor ウィジェットしか無さそうだったりしてちょ2025-03-06(Thu)
-
TypeSpecblog4 を typespec に書き直してみた。 OpenAPI を直接手で書くのはまぁまぁ大変というかゴチャゴチャしがち。 typespec を使うと DSL で書けて綺麗に書ける気分になる。2025-03-04(Tue)
-
Copilot Language Server SDKこういうの良いよね。特定のエディタにロックインされずにすむのはありがたい。 実際ちょっと IDEA の github copilot 拡張は挙動がちょい怪しかったんだけど(過去形)、そういうときに2025-03-03(Mon)
-
Comic ScreenAndroidで、BookScan でスキャンしたマンガを見開きで読むにはこれが良さそう。 PerfectViewerというのもあるんだけど、機能がごちゃごちゃしててなんか難しかった。2025-03-03(Mon)
-
自分のブログを golang でかきなおしてさくらの AppRun でホスティングするようにした転職前にこのブログを Sveltekit で書き直したのだが、転職したら golang で仕事をすることになり、golang に慣れる必要性を感じた。 というわけで自分のブログを golang でちま2025-02-28(Fri)
-
btop2025-02-26(Wed)
-
sphinx の検索に unicode normalization を導入するパッチを書いたsphinx-doc は全文検索機能を自前で実装している。現在、文字種の正規化機能がないため、例えば `IP` と書いてあったときに `IP` というキーワードで検索出来なかったりする。 近年では2025-02-24(Mon)
-
Obsidian のライセンス変更の件> Starting today, the Obsidian Commercial license is optional. Anyone can use Obsidian for work, f2025-02-21(Fri)
-
com.github.johnrengelman.shadow は com.gradleup.shadow に変わっていた> Previously this plugin was developed by @johnrengelman and published under the ID com.github.joh2025-02-20(Thu)
-
BOOX GoColor7 買った2025-02-18(Tue)

-
ASGIAsynchronous Server Gateway Interface。 WSGI の非同期対応版。2025-02-18(Tue)
-
Mac で mise install php する方法```sh brew install autoconf automake bison freetype gd gettext icu4c krb5 libedit libiconv libjpeg l2025-02-14(Fri)
-
Evidencean open source framework for building data products with SQL だそうで。 SQLを書いた markdown をもとに、データソースから2025-02-13(Thu)
-
rye より uv という話rye よりも uv のほうが良いらしい。 でも、mise を使い始めた ので、両方今使ってないのだった。2025-02-12(Wed)
-
Task を go get -tool で入れる```sh go get -tool github.com/go-task/task/v3/cmd/task@latest ``` とかして入れる。 ```sh go tool task ```2025-02-12(Wed)
-
mise を使い始めた色んなインタープリタなどのインストールは必要なわけだが、、 anyenv, asdf などあるのは知っていたが色々入れてたのだが、mise を使い始めた。 体験がいいかも。 ```sh brew2025-02-11(Tue)
-
パスキーのすべて、を読んだ2025-02-09(Sun)

-
Markdown でスライドを書ける Marp を使い始めた最近は AI が全盛だよねえというところもあり、テキストで生成できるツールでスライドを作るようにしようかなぁと思って Marp を使うようにしてみた。 前職のときはスライドを Box で共有できること2025-02-08(Sat)
-
Redis の lua で printf debug する方法Redis または Valkey では lua を使うのが便利なわけだが、デバッガがまぁまぁダルい。 printf debug するには以下のようにする。 ```lua redis.log(redi2025-02-07(Fri)
-
arc42 by Examples2025-02-06(Thu)

-
arc42 - Architecture 文書のテンプレートドイツで流行ってるっぽいアーキテクチャ文書のテンプレート。 必要十分なフォーマットだと思う。 Diagrams.net Integration for IntelliJ の文書がこのフォーマッ2025-02-06(Thu)
-
BOOX Go 7 Color を買った2025-02-06(Thu)

-
Diagrams.net Integration for IntelliJdiagrams.net(旧称: draw.io) を intellij の中で書けるんだけど、オフラインで動作する。 で、foo.dio.svg/foo.dio.png みたいなファイル名だった2025-02-04(Tue)
-
Java 用の File Leak DetectorJava agent として動作するとのこと。 > In addition, upon a "too many open files" exception, this agent will du2025-02-04(Tue)
-
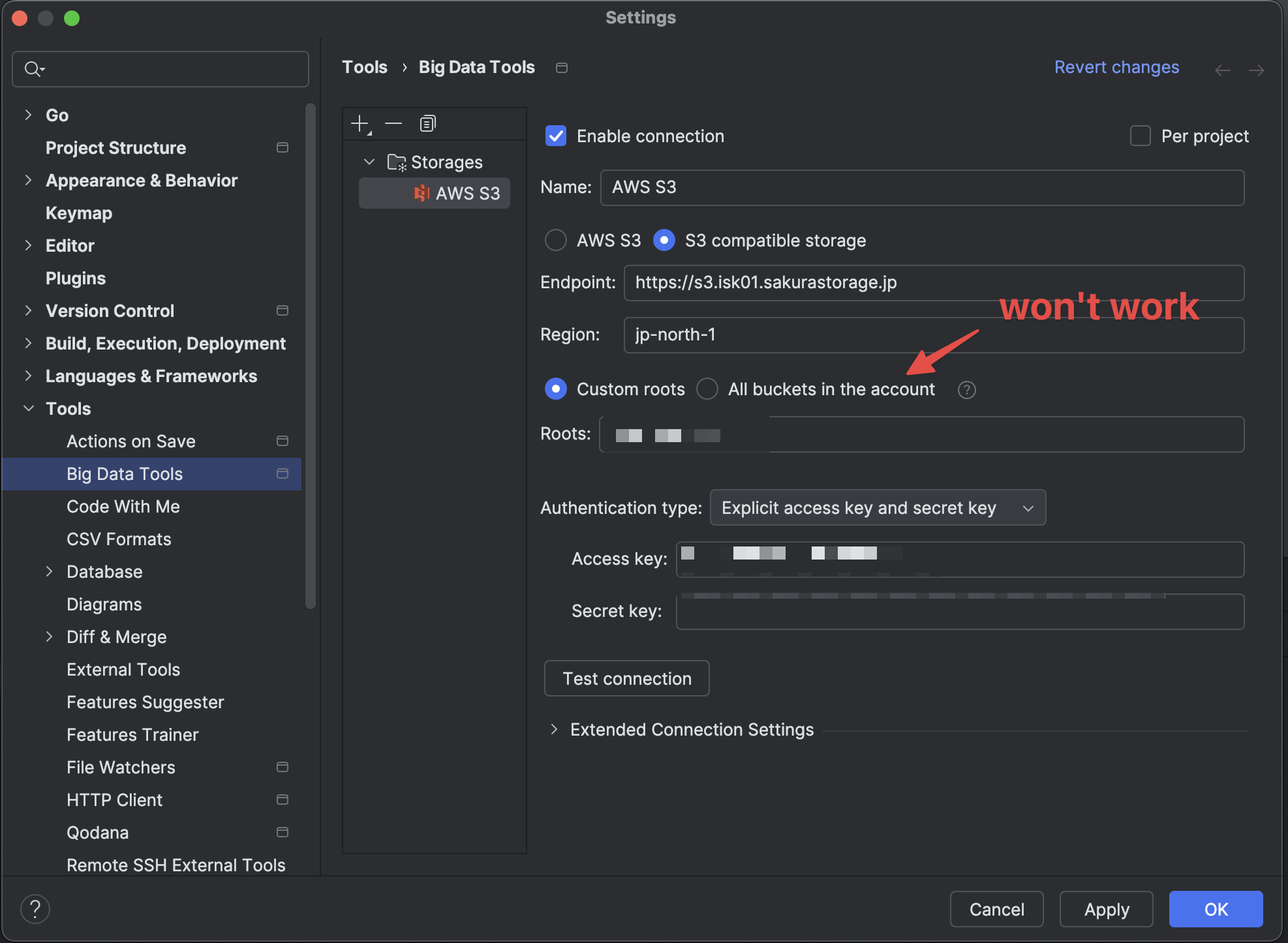
さくらのオブジェクトストレージに GoLand 等からアクセスする方法2025-02-03(Mon)
-
コロンビア オークハーバー2 を買った2025-02-02(Sun)

-
github の通知を mac でスッと受け取りたい# gitify なんか GUI アプリとしての作り込みがちょっと甘いかも。 普通の mac アプリっぽい挙動になってないところがある。 あと、 github.com のアカウントの同期をしたあと2025-02-02(Sun)
-
gorilla/feedsgolang の RSS 生成ライブラリ。blog4 で採用しようかなと。 普通に使いやすくて良い感じ。2025-01-31(Fri)
-
プログラミング関連ドキュメントをオフラインで閲覧出来る devdocs が便利だったzeal が mac で使えないので他の dash alternative を探していたら、devdocs.io が良さそうということがわかった。 `brew install --cask dt2025-01-30(Thu)
-
zealdash みたいなドキュメントビューアー。無料で使えるっぽい。 Dash が有料なので、zeal 良いかもなぁとおもって見ていたら、Mac では使えないらしい。 windowsとlinuxで使える2025-01-30(Thu)
-
仕事用のメモを logseq 使うようにした結局、logseq で良いかなぁ、と。 git commit を自動的にしてくれる機能もあるんで、commit はそれで自動的にやらせつつ git push だけ cron で実行するようにする。2025-01-30(Thu)
-
jetstream + LAMY 届いた2025-01-29(Wed)

-
Chrome Web Store for Enterprise 7> 企業の従業員などが、IT部門などがあらかじめ許可したGoogle Chromeの拡張機能の一覧を参照し、必要に応じてChromeブラウザにインストールできる新サービス これは、機微な個人情報2025-01-28(Tue)
-
SRE Kaigi 2025 に参加した2025-01-27(Mon)

-
新しいリュックを買った2025-01-26(Sun)

-
Topo Mini - めっちゃ良い感じのスタンディングデスク用マット2025-01-25(Sat)

-
入門Opentelemetry2025-01-24(Fri)

Prev