-
mutsu に Test.rakumod をバンドルしようとしている2026-08-02(Sun)

-
DBIish をバンドルした mutsu 0.20.0 を出した2026-07-30(Thu)

-
ブログの DB を TiDB に移行した2026-07-24(Fri)

-
mac-akaza v2026.723.0 をリリースした2026-07-23(Thu)

-
og:image のレンダリングロジックを更新2026-07-23(Thu)

-
opencode でカーソルが blink してるのを止めたかったけど原因は WezTerm だった件2026-07-23(Thu)

-
tagpr の versionFile がわかりにくかったのでドキュメントPRを出した2026-07-21(Tue)

-
自作 macOS IME Akaza がスリープ復帰後に死ぬ問題を数週間追いかけたら、犯人は IME じゃなかった2026-07-13(Mon)

-
ログイン時に起動するオプションをつけた ShotShot v2026.610.0 をリリース2026-06-10(Wed)

-
mac-akaza v2026.604.0 が出てます2026-06-04(Thu)

-
akaza v2026.602.0 が出てます2026-06-02(Tue)

-
akaza v2026.530.0 を出しました2026-05-30(Sat)

-
mac-akaza v2026.519.0 が出ました2026-05-20(Wed)

-
カリオストロ方式 「異議なき時は沈黙をもって答えよ」2026-04-08(Wed)

-
mac-akaza v2026.331.0 を出しました2026-03-31(Tue)

-
Mac Akaza v2026.327.0 を出しています2026-03-27(Fri)

-
詰将棋生成アプリと、詰将棋サイトを作った。2026-03-16(Mon)

-
鉄塊機関 ―IRON FORGE ENGINE― というゲームを作ってみた。2026-03-14(Sat)

-
vite-bundle-visualizer で vite で bundle したファイルのサイズを visualize する2026-03-12(Thu)

-
マッチ3パズルとローグライトなゲームを作ってみた2026-03-07(Sat)

-
ShotShot で URL からの起動ができるようになった2026-03-04(Wed)

-
ATOK Passport [プレミアム] を解約した2026-03-02(Mon)
![ATOK Passport [プレミアム] を解約した](https://blog-attachments.64p.org/og-images/2026/03/02/005739.png)
-
ShotShot という Mac 用の Skitch みたいなスクリーンキャプチャツールを開発した2026-02-26(Thu)

-
connectrpc が便利そう2026-02-25(Wed)

-
wrapguard - LD_PRELOAD を使ったユーザーランドで動く VPN proxy2026-02-25(Wed)

-
CPAN Module を Deprecate する方法2026-02-25(Wed)

-
ShipIt が "Upload failed." で死ぬ時2026-02-24(Tue)

-
akaza v2026.218.1 をリリースした2026-02-19(Thu)

-
chrome で見たページの履歴を全てとっておく Archivist というツールを作った2026-02-13(Fri)

-
skip-bigramを入れた akaza 0.5.0 が出た2026-02-12(Thu)

-
akaza 0.3.0 をだした2026-02-10(Tue)

-
goland のターミナルで Activate virtualenv すると mise で入れたモノに PATH が通らなくなる2026-02-10(Tue)

-
qemu の -netdev は ipv6=on にすると ipv4 はオフになる2026-02-10(Tue)

-
akaza 内部で FxHash を使うことにした2026-02-08(Sun)

-
rsmarisa 0.4.0 を出した2026-02-08(Sun)

-
rsmarisa 0.3.0 で高速化された2026-02-07(Sat)

-
自作IM Akaza 0.2.3 を出した。2026-02-06(Fri)

-
Pop_OS! 24.04 にする2026-02-04(Wed)

-
JetBrains IDE でつかえる fizzier に 2.0.0 で非互換の変更が入っていた2026-02-04(Wed)

-
colima で docker-compose 使う2026-02-04(Wed)

-
自作IM akaza の 0.2.2 を出した2026-02-04(Wed)

-
linux のキーリマッパーは keyd がいいかも2026-02-02(Mon)

-
home-manager で dotfiles をリンクさせるのをやめた2026-02-01(Sun)

-
Dashyard2026-01-31(Sat)

-
difit を使い始めた2026-01-30(Fri)

-
ブログの編集画面を htmx から preact にした2026-01-29(Thu)

-
marisa-trie を rust に移植してみた2026-01-28(Wed)

-
og:image 生成するようにした2026-01-28(Wed)

-
`devbox search yq` とかしたときに詳細がわからなすぎたときの対策2026-01-27(Tue)
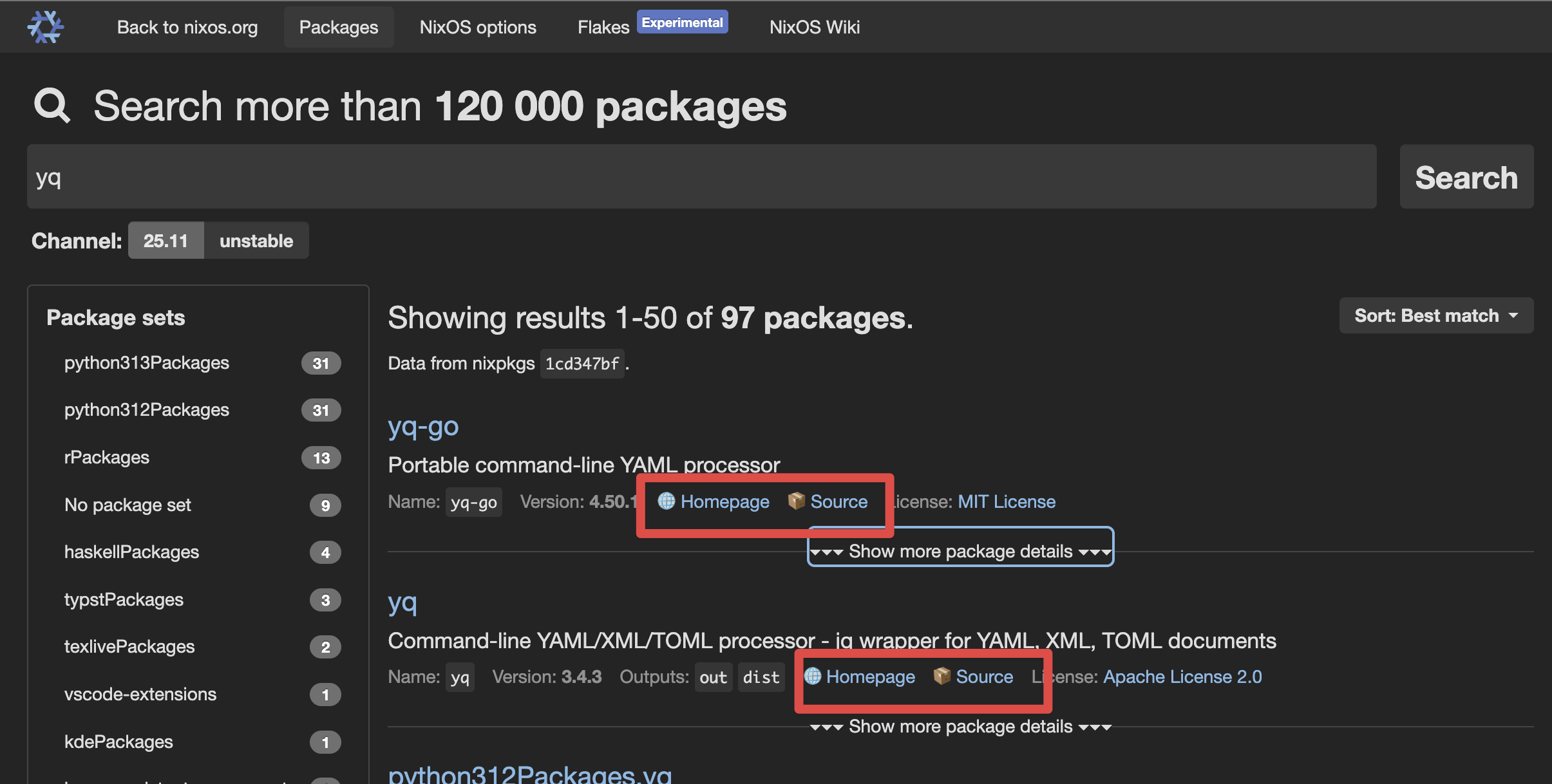
-
Pop! OS で、入力ソースを追加する2026-01-27(Tue)
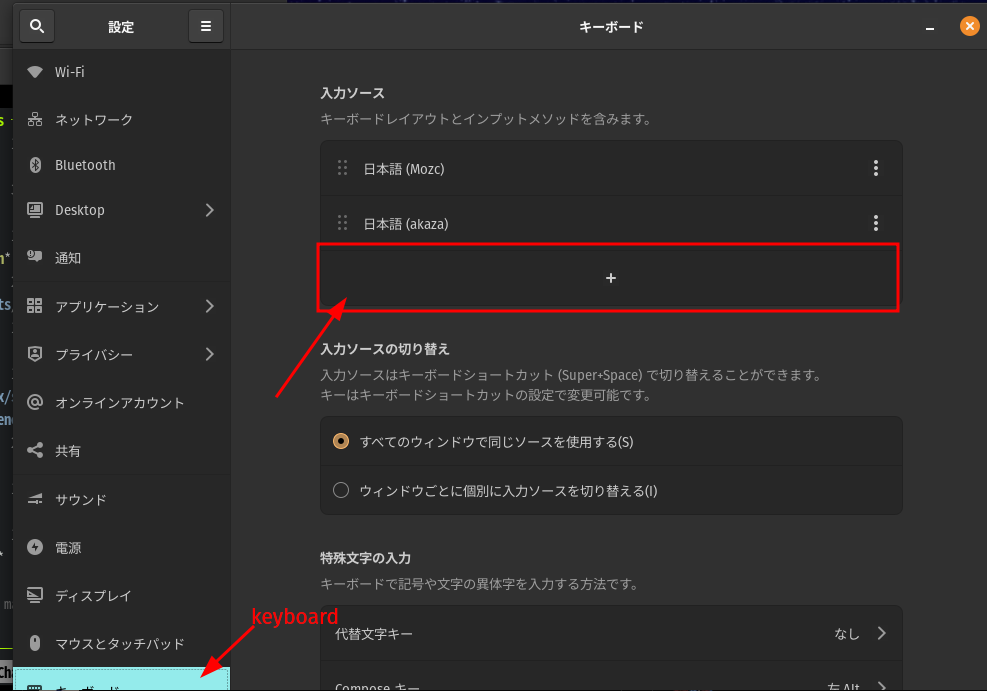
-
ogp を設定した2026-01-26(Mon)

-
開発者間でツールのバージョンをそろえられる devbox 使い始めた開発時に、`go install` とかで go で書かれたツールをちょいちょい入れてたんだけど、go 自体のバージョンを mise で上げたら再インストールする必要があってダルかった。 を参考に2026-01-26(Mon)
-
モニタリングスイート連携を追加した SakPilot 0.0.11 をリリースした2026-01-25(Sun)
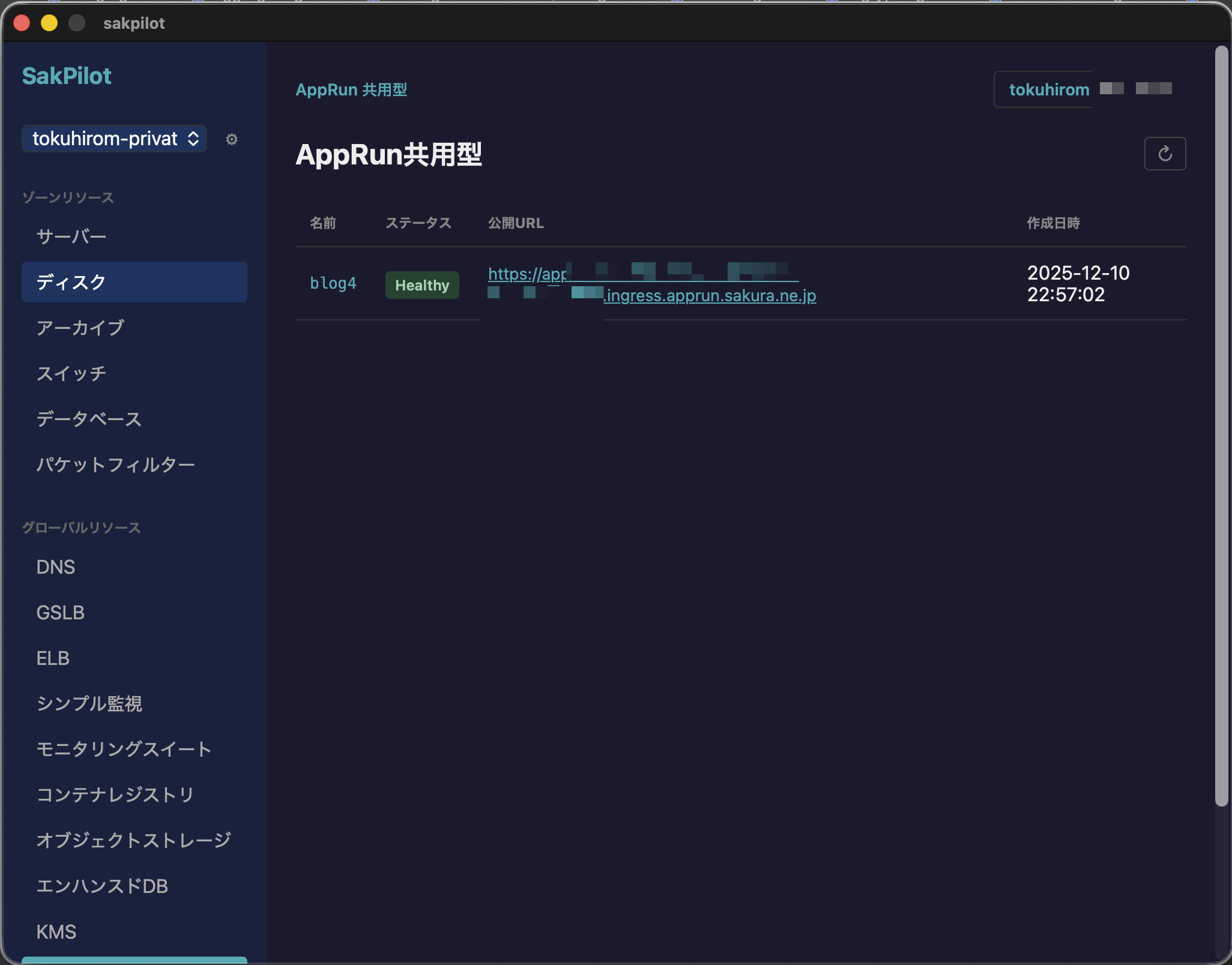
-
AeroSpace やめて HammerSpoon でウィンドウ管理することにしたAeroSpace ちょっと使ってたんだけど、、よく考えると別にタイル型ウィンドウマネージャーそんなに好きじゃ無いかもって思って、構成変えました。 俺、本当はタイリングよりも ratpoison 好き2026-01-25(Sun)
-
ソリティアを実装したclaude codeで。 ウェブで遊べる。github pages にデプロイされてる。 vite, TypeScript。 なんでわざわざ作ったかというと、特に理由はなくて、mineswe2026-01-24(Sat)
-
DB スキーマのマイグレーションをオブジェクトストレージ経由で行う dbmate-deployer を作ったやりたいこととしては、以下の通り。 * DB の schema migration をサーバーにログインせずに行いたい。 * github actions からは DB に直接アクセスしたくない2026-01-23(Fri)
-
Aerospacei3 系のタイルウィンドウマネージャー。Mac 用。 JankeyBorders も入れる。 ghostty は aerospace と相性が悪くて、タブごとにウィンドウとして扱えるという地獄のよ2026-01-20(Tue)
-
AI で nix に移行する、Vibe nix してみた去年、nix 使ってみようと思ったけど謎エラーが出て諦めてしまっていた。 nix だとDSLを覚える必要がある上に、エラーメッセージがあんまり親切じゃないので、エラーになりすぎて諦めてしまっていた。2026-01-20(Tue)
-
ターミナルを wezterm に戻すAerospace だと ghostty も alacritty も挙動不審でタブごとにウィンドウが生成されてしまって使いにくすぎるんで、Wezterm に戻した。 まさか、ウィンドウマネージャのた2026-01-17(Sat)
-
aerotag を使おうと思ったけど挫折して自前でゴリゴリ書いたを見て、aerotag 良さそうじゃん、と感じた。 ワークスペースにそれぞれ割り付けるよりも、モニターごとにワークスペースを固定して、アプリケーションごとに表示/非表示を切り替えるというのがよさそう2026-01-14(Wed)
Prev