-
TinyURLをつくってみよう 〜 軽量フレームワークAmon2入門 (4) 〜2011-07-14(Thu)
-
Amon2::DBI からはじめるデータベースアプリケーション 〜 軽量フレームワークAmon2入門 (5) 〜はい! というわけで3連休あけですね。 Ruby 会議にいったり、Android なんとかにいったり、リア充生活をおくったりと、各自たのしい3連休をすごされたことかとおもいます。 さて、連休あけの今2011-07-19(Tue)
-
Amon2::Setup::Flavor::Large + Teng をもちいた簡単な掲示板の作成 〜 軽量フレームワークAmon2入門 (7) 〜前回から大分時間が経ってしまいましたが、唐突に Amon2+Teng で大きめのアプリをつくるチュートリアルでもはじめましょう。Teng というのは、O/R Mapper とよばれる種類のライブラリで2011-11-20(Sun)
-
Amon2 に local context mode をつけた### 問題 Amon2 のプロジェクトを2つ Plack::Builder で mount してつかいたい、みたいなときにコンテキストがどっちかこんがらがったりしそうかなーっておもったりしたんで。2013-02-13(Wed)
-
Split Amon2::Plugin::Web::CSRFDefender from core distribution.## 1. Amon2::Plugin::Web::CSRFDefender was removed from Amon2 core distribution. Amon2::Plugin::Web2014-11-28(Fri)
-
dotcloud で Amon2 をつかう!Perl5 の PSGI アプリケーションが死ぬほど簡単につかえる dotcloud の beta 版がリリースされ、一部の Perl monger に invitation がばらまかれているととも2011-05-01(Sun)
-
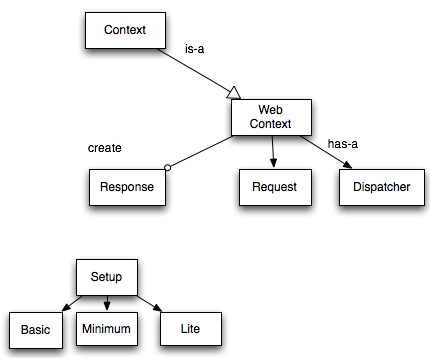
Amon2のアーキテクチャとトリガ機構 〜 軽量フレームワークAmon2入門 (2) 〜2011-07-12(Tue)
-
Amon2 がストリーミングに対応しました。最近、Amon2 のリアルタイムWebサポートをおこないました。 これにより、WebSocket や Long poll をつかうウェブアプリケーションを Amon2 で簡単にかくことができます。2012-08-08(Wed)
-
Amon2 の最近の変更(3.22〜3.25)* Amon2::Lite が別 dist に分離されました(Amon2::Lite をつかっているアプリでは Amon2::Lite への依存を明示的に記述するようにしてください) * 各種依存がす2011-11-14(Mon)
-
Hasegawa方式の CSRF対策を試してみたAmon2 での実装例です。 使用感としては、 * 実装はそれほどむずかしくない * トークンの保存をサーバー側でやらなくていいので楽 といったかんじ。 管理画面とかでつかってみたらよいかもし2013-03-04(Mon)
-
Amon2::Lite というモジュールを Amon2 に添付してみました。まだ EXPERIMENTAL な実装なので今後かわる可能性もありますが、とりあえずリリースしました。 [ Sinatra や Mojolicious::Lite のような感じで、以下のように a2011-07-10(Sun)
-
Amon2 is now Carton ready - Amon2 3.74 is out[ I shipped Amon2 version 3.74, today. This version of Amon2::Setup creates cpanfile to support Ca2013-03-02(Sat)
-
Amon2::Auth によるロケタッチAPIをつかったサイトの構築 〜 軽量フレームワークAmon2入門 (6) 〜[ 久々に Amon2 入門だ! 最近リリースされたばかりの Amon2::Auth モジュールをつかってみよう! Amon2::Plugin::Web::Auth への依存を Makefile.2011-10-16(Sun)
-
Amon2 が WebSocket に対応していた!!Amon2::Plugin::Web::WebSocket というプラグインをだしました。 Amon2 の中で非常に簡単に web socket がつかえます。 なんかよくわからん作法とかおぼえ2012-08-07(Tue)
-
唐突ですがここでプラグインをかいてみよう 〜 軽量フレームワークAmon2入門 (10) 〜Amon2 のプラグインの書き方がよくわからないという話をたまに聞くので、そのへんについて説明したいとおもいます。 基本的にはプラグインはただの Perl モジュールで、ただ一つの規約にしたがえば問2011-11-25(Fri)
-
Amon2 2.13 でた[ perl 5.10 以後でどうにゅうされた "//=" をなぜか script/amon2-setup.pl でつかってたのを修正した。 【追記】 dor ってかくと、結局うせた dor2011-01-28(Fri)
-
Amon2 with XMLRPC[ Amon2 で XMLRPC をつかうには、RPC::XML をつかえばよろしい。context object は CLI などとおなじく MyApp->bootstrap() でいける。2011-02-28(Mon)
-
[Security Notice] Amon2, HTTP::Session2 security updatesLast week, I shipped Amon2 and HTTP::Session2 includes security fix. ## [Must] Update "secret" if y2014-11-28(Fri)
-
Amon2::Lite の最近の変更とか[ なんかこういうのかいてみたんだけど、どうも、ださい書き方を強要されているところがあって、いけてないかんじがしたのでちょっと調整した。 具体的にいうと ``` $res->h2011-11-19(Sat)
-
Amon2 の最近の変更のまとめ(2.13〜2.23あたりまで)* デフォルトのテンプレートを HTML5 に変更 * Tiffany への依存をなくした * [ を充実させた(using sphinx) * DBI へ依存してみたが、XS 依存しない方針だったこ2011-02-27(Sun)
-
Amon2::Lite をつかった TinyURLAmon2::Lite を使いやすくしたいなあ、とおもって小物をちょっとかいてみる。まあ、こんなもんかなあ。もうちょいうまく書けそう、という部分もなくはない。 オシャレポイントとしては * DBD2011-11-19(Sat)
-
Amon2 の最近の変更点まとめ(3.06〜3.21)英語で Changes かいてますが、たまには日本語でまとめておきます。 * 徳丸本をよんでて「そういえば」とおもったので、Cookie に HttpOnly 属性をデフォルトで付与するようにした2011-11-09(Wed)
-
Amon2 のデフォルトの CSS framework を twitter の bootstrap にかえた2011-09-23(Fri)
-
Shipped Amon2::DBI 0.30, and it contains incompatible changes.Amon2::DBI 0.30 uses RaiseError for handling exceptions. Older Amon2::DBI's exception handling is co2012-10-20(Sat)
-
Amon2 switched to Module::BuildAmon2 switched to Module::Build. Be carefully. And amon2-setup.pl generates Build.PL instead of Mak2012-11-12(Mon)
-
Amon2 で bootstrap を明示的によぶケースAmon2 で bootstrap しているのは、dbh などのリソースのキャッシュのためというのが大きいです。 ですから、無闇に bootstrap メソッドをよびまくるとおかしいことになります。2012-12-27(Thu)
-
Amon2 5.05 was out.Default routing engine was switched to Router::Boom. Router::Boom is faster than Router::Simple. We2013-10-28(Mon)
-
Shipped Amon2 6.00Shipped Amon2 6.00. This release contains the big change. Amon2 switched to default session managem2013-12-13(Fri)
-
Amon2 の構成今、こうなっている。 基本的には魔法をつかわず、pluggableで minimalistic というところで、現状のものであんま不満はないのだが、つかってるモジュールをちょっとかえるかも。具体的に2010-11-25(Thu)
-
Amon2 近況(2)Amon2 のポリシー的なものとして * 既存のアプリがうごかなくなる変更をするときはネームスペースをかえる * 小さなサイトから大きなサイトまでつくれるようにする * PP でもうごく といった2011-10-07(Fri)
-
Amon2 について WEB+DB プレスにかきました2012-12-26(Wed)

-
Amon2とJSONとセキュリティ* \[1\][ * \[2\][ * \[3\] [ * \[4\] [ あたりをよんで、JSON とセキュリティについてかんがえてみた。 ここで、有効とされている対策のうち * while(2011-11-25(Fri)
-
2011年のまとめ1月 * Teng をリリースするのにかかわってたっぽい * libkyototycoon であそんでた * Text::Darts をなおしたりしてた 2月 * L10N やってた [ * W2012-01-01(Sun)
-
Why does Amon2 generates .psgi file, but Mojolicious does not generate it?> 素朴な疑問Amon2はpsgiファイルが雛形でつくられるけどMojoliciousではgenerate appで何故つくられないんだろ?。 > — dokechin (@dokechin) [Fe2013-02-28(Thu)
-
Amon2 により CSV を PSGI/Plack で出力する方法Amon2::Plugin::Web::Streaming と Text::CSV\_XS の組み合わせにより、ストリーミング出力が可能です。 (Streaming 出力をサポートしたサーバーをつかっ2013-04-06(Sat)
-
HTTP::Session2 has been released.English document is available on [metacpan]( Following document is written for non-english speakers2013-10-28(Mon)
-
Amon2::Lite->template_optionsI added template\_options method for convinience. ``` use Amon2::Lite; __PACKAGE__->template_optio2011-11-16(Wed)
-
Amon2's current statusI optimized amon2 to dotcloud at latest few releases. I don't have any future plan to develop it. D2011-06-13(Mon)
-
Amon2 のドキュメントにガラケーむけの記載を追加[ ガラケーでの開発時にめんどくさいところは Amon2 ではプラグイン等により吸収しています。 HTTP::MobileAgent との連係、文字コードの追加、全角カタカナから半角カタカナへの2011-09-25(Sun)
-
Plack::Middleware::* と Amon2::Plugin::* のつかいわけ勝手に後夜祭で質問いただいたのでブログにもかいておく。 Plack::Middleware::\* は、apache の設定にかくようなものをいれる。 * テンプレートエンジンをつかうもの * 設2011-10-16(Sun)
-
Amon2 4.00 releasedAmon2 が久々のメジャーバージョンアップをはたしました。 主な目玉としては、 * Teng をデフォルトの O/R Mapper として採用 * bootstrap 3 に対応 の二点で2013-08-27(Tue)
-
Amon2 にStandalone フレーバーが追加されたAmon2 4.04 から、EXPERIMENTAL ではありますが Standalone フレーバーが追加されました。 これにより、CPAN にすぐあげられる状態のウェブアプリケーションが生成され2013-10-09(Wed)
-
Amon2 5.01 was released!!!Amon2 5.01 was released on CPAN. Core features are: * Default jQuery version is now 2.0 * Defaul2013-10-28(Mon)
-
Perl でつくった web サイトを L10N する方法Perl でつくった web サイトを L10N する方法について簡単に説明します。今回は、日本語のサイトを英語でも表示できるようにするケースをあつかいますよ。今回は L10N の対象は Amon22011-02-24(Thu)
-
Ukigumo の demo サーバーを用意しました[ Ukigumo 結局どういう風にうごいているのか社外の人にはようわからんじゃろうとおもったので、デモサーバーをおいてみた。dotcloud においただけだけど。 Ukigumo の場合、Am2011-09-12(Mon)
-
Amon2 の今後のバージョンアップ予定Flavor まわりを大幅にぜんぶかきかえてます。互換性は保証されませんが、アプリケーションには影響しないのでいいのかなとおもっているところです。 Data::Section::Simple をつ2011-10-02(Sun)
-
Amon2 近況#### テンプレートカスケーディングやめました テンプレートカスケーディングをつかってゴリゴリがんばる、みたいなのをやってみたんですが、どうも複雑になりすぎるのでやめました。 #### Larg2011-10-08(Sat)
-
XSS フィルターを解除するには X-XSS-Protection: 02012-07-06(Fri)

-
Amon2::Setup::Flavor::Large + Teng をもちいた簡単な掲示板の作成 その2『ページャーをつけよう』 〜 軽量フレームワークAmon2入門 (8) 〜さて、掲示板をつくったとはいえ、これだけではおもしろくありませんね。 まずこの掲示板には重大な欠陥があります。具体的にいうと、ページングがされていません。 ウェブアプリケーションにおいてはページ2011-11-21(Mon)
-
俺が普段よくつかう JS を Amon2 ジェネレーターでだすようにした普段、JS をつかってるときによくつかってるスクリプトたちを Amon2 でスケルトンつくったときにだすようにしておいた。 でっかいものじゃなくて、簡素なユーティリティ的なものだけをとりいれています2012-08-06(Mon)
-
Amon2 をつかったウェブアプリケーションを GUI アプリにはやがわりさせる!!GUI アプリをつくりたいけど、どうもめんどくさくて、ウェブアプリケーションですませてしまうウェブエンジニアは多いとききます。 とはいえブラウザでいちいちひらくのも面倒だし、daemontools2012-08-09(Thu)
-
Class::Data::Lazy has been released.[Class::Data::Lazy 0.01]( has been released on CPAN. It's very useful when you are writing the Amon2013-12-13(Fri)
-
Encode::encode で変換できない文字を 〓 にする``` use utf8; use Encode; my $geta = Encode::encode($encoding, '〓'); Encode::encode($encoding, $str2010-11-26(Fri)
-
Amon2::Plugin::Web::NoCacheとりあえずデフォルトでつかうのやめた。X-Frame-Options とか X-Content-Type-Options とかをデフォルトでつけるのを最近はじめているので、あまり NoCache だけ2011-11-09(Wed)
-
Cache-Control ヘッダAmon2 ではデフォルトの Cache-Control ヘッダを no-cache にしていたのだが、なにかにつけてうざいかんじになっていたので private をデフォルトにした。これでおーけーで2011-11-10(Thu)
-
Amon2 の最近の変更について* LogDispatch, Web::MobileAgent, Web::MobileCharset の各プラグインがコアからはずされて別distになりました * スケルトンの Makefile.P2011-05-15(Sun)
-
Catalyst が Plack に依存したCatalyst 5.90001 がでまして、こちらのバージョンは Plack に依存しております。これは非常に PSGI プロジェクトにおいてはひとつの節目となるリリースといえましょう。HTTP::2011-08-16(Tue)
-
State of Tiffany.pm@miyagawa san introduced Tiffany.pm in YAPC::Asia 2012, thanks. The state of Tiffany.pm is stable.2012-10-01(Mon)
-
Shipped Teng::Plugin::TextTableI shipped Teng::Plugin::TextTable 0.01. You can dump a database data as text table. It's useful2012-11-15(Thu)
-
Amon2 3.34 releasedbootstrap 2 系に対応させたのが主な更新です。jquery も 1.7.1 から 1.7.2 にあげておいた。2012-03-26(Mon)
Prev